ゲス顔イオナズン
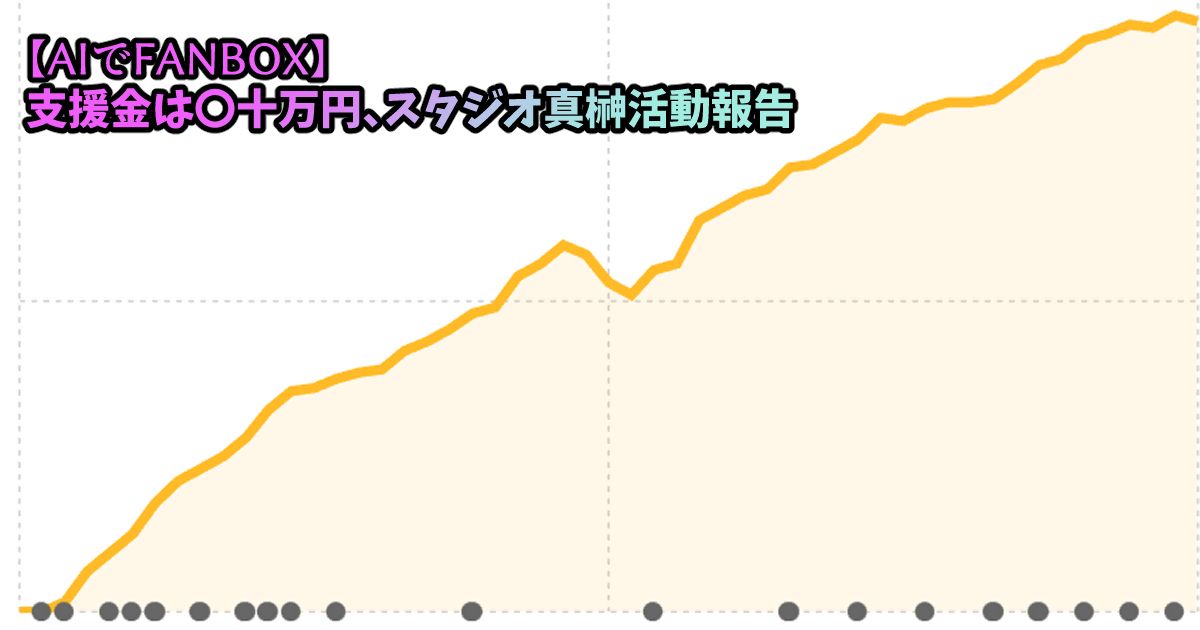
Stable Diffusion✕AIイラスト徹底解説!
 |  |  |
 |  |  |
 |  |  |
【StableDiffusion導入解説】NovelAI中級者がローカル環境を導入したら別世界に突入した件 いつもブログを見てくださっている皆様こんばんは、スタジオ真榊です。前々から「ローカルやりたい」「やらなきゃ」「でもマシンパワーがな~」「NAIちゃんじゃないと顔が統一感なくなっちゃうしな~」と言い訳ばかりしてきたのですが、昨晩一念発起してついにローカル環境を導入しました。 悪戦苦闘の末に得られたものは…いや~…言葉が…言葉がありません! なぜ私はローカル環境をもっと早く導入しなかったのか? いま私の目の前の箱で、NAIをはるかに上回るエチチ画像が無数に生成されております。みんなこんなことやってたの!?最高じゃあん! というわけで、本日はNovelAIで画像生成に慣れてきた人向けに、ローカル環境を導入する方法と、それによって何が得られるのか?ローカル環境はなぜ素晴らしいのか?について書いていきますよ! 2023/01/24:「プロンプト記法の違い」を追記し、全体に内容を修正・詳細化しました。 
 まず記事を始めるにあたって、最初に御礼から書かせていただきます。
ツイッターでこちらのバカみたいな投稿をしたところ、かけうどん様、zzz AIお絵描き(drawing)様、CONV(こんぶ)@AIart様、Canpon1992X様、マチネ フク様、ツバサ天九様、きせのん様、桃色りりあ様、Myrr.様、もりそば@AI画像垢様、moriπ様(順不同)ら大変多くのAI術師の皆様が温かく教えてくださり、さまざまなつまづきが一気に氷解しました(リプ欄参照)。ここに書ききれないほど優しい応援を頂いて、本当にありがたかったです。重ね重ね御礼申し上げます。
そんな賢者の皆様のお助けによって一夜漬けでようやくローカル環境整備にたどり着いた私が、ローカルのハウツー記事を書くのは本当にアレなのですが、「初心者がやってみたらこうだった」というスタイルで書くことで、同じくこれからローカル環境に踏み入る方向けに少しでも有用な情報が残せるのではないかと思いますので、恥ずかしがらずに書いていきたいと思います。 はじめに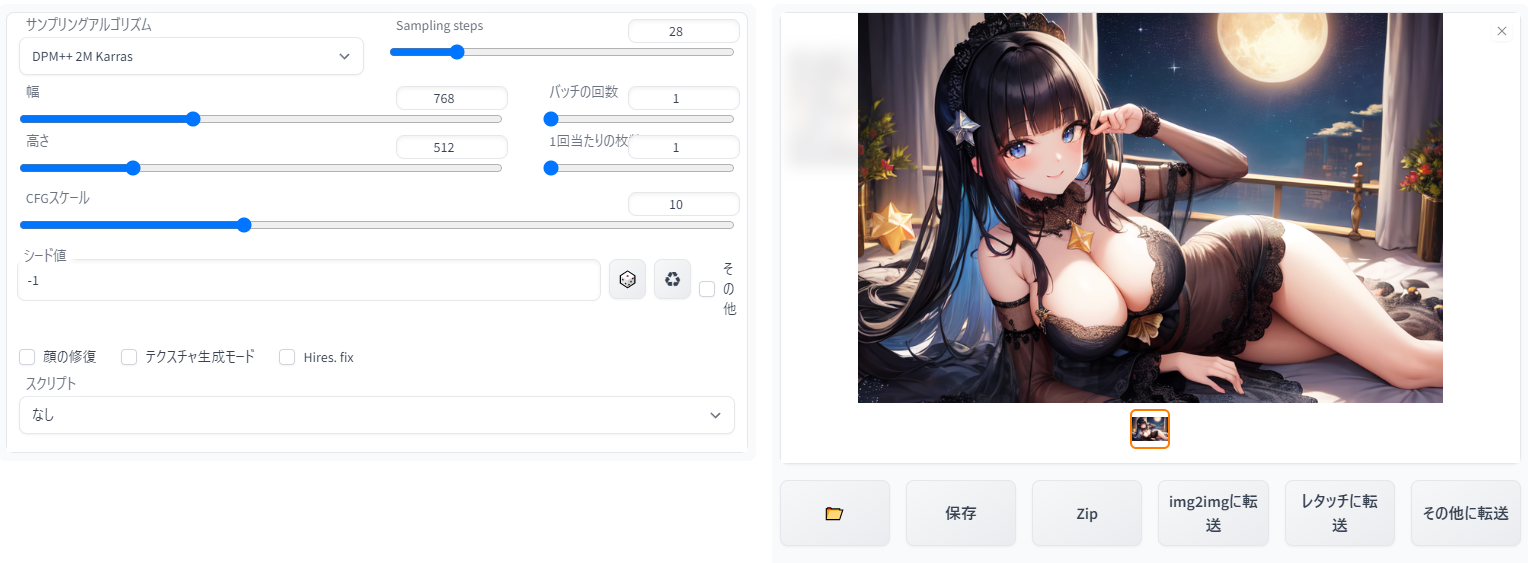 ローカル環境と一口にいっても様々な方法がありますが、この記事では、Stable Diffusionを簡単に操作でき、「画像内の一部だけレタッチ」などのNAIにはできない生成法が可能になる「Stable Diffusion web UI」の導入方法を初心者向けに紹介します。賢木がつまづいたポイントなどに触れながら、肝心などすけべH画像を無料かつ無限に生成するまでの道のりをたどれればと思います。 Stable Diffusion web UIをローカル環境で動かすには、「Stable Diffusion web UIのソースコード」「Stable Diffusionのモデルデータ」「Python(パイソン)」「git」「NVIDIA製GPU(GeForceRTXシリーズetc)」をそろえる必要があります。この時点で「なんだそりゃ何ひとつわからん」状態の方も多いと思うのですが、賢木も同レベルなので大丈夫。ざっくり説明していきましょう。 さて、SD web UIは、さまざまな画像生成AIの学習モデルを放り込むことで動作します。ハッキングで流出したとされるNovelAIのモデルを使えばNAI風の画像を作ることすらできますが、他にもさまざまな特徴を持つ学習モデルが続々と登場しており、さらにそれらを混ぜ合わせて自分だけの独自モデルを作ったり、さらにそれを配布したりすることが盛んに行われています。言ってみれば「SD web UIがゲームハード、学習モデルがゲームソフト」のような関係で、複数のソフトを悪魔合体して自分だけの新ゲームを作ることもできるよ、ぐらいの理解で大丈夫です。ゲームだと考えれば、ある程度の性能を持ったNVIDIA製GPU(GeForceRTXシリーズetc)が必要になるのも当然ですね。 「Stable Diffusionのモデルデータ」は、ゲームを始めるにあたって最初に放り込む基本ソフト。「Python(パイソン)」はAI開発に使われるプログラミング言語。「git」はファイルのバージョン管理が簡単にできるツール。これらが揃うと、晴れて自分のPC内で無料無限にえちち画像が生成できると思ってもらえればOKです。 何ができるの?NAIとの違いは?「スマホでも画像生成できるNovelAIがあるのに、なんでわざわざグラボを買わないとまともに動かないローカル環境を整備しないといけないの?」と思われる方がいらっしゃると思います。私もまさにそんな理由で手をこまねいていたので、環境が許すならローカルに挑戦すべき理由を先にお話ししたいと思います。 結論から言えば、 「NovelAIのマスピ顔を卒業できる(重要)」 「無料で無限に画像が生成できる」 「forever生成にすれば、外出中も家でエロ画像が生成され続ける」 「ダウンロードボタンが必要なく、生成した画像はPC内に自動保存される」 「画像サイズが自由。UI内でサイズアップすることも可」 「画像の一部だけを指定してi2iができる(指や顔の差分修正が超かんたん)」 「学習モデルを選ぶことで、イラストやnsfwなど目的に合わせた絵柄開発が可能」 「多くの追加便利機能を自由に選ぶことができる」 というのが主なメリット。そして、エロ特化のモデルを導入すれば、NAIで苦心するよりもはるかにかんたんにドチャクソエロ画像が生成できます。NAIマニアの皆さんが慣れ親しんだ{}での強調が使えないなど、NAIとプロンプトのルールは少し違いますが、NAI語からWebUI語にする翻訳機能もあるので、NAIが使える方なら問題なく活用できるかと思います。 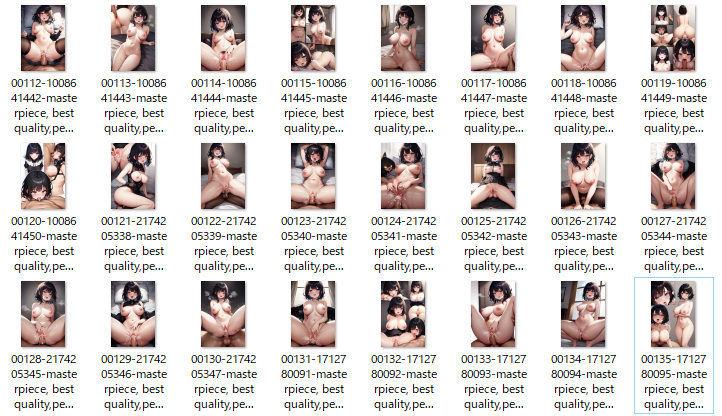 こちらは現在も賢木のPCで生成され続けているえちち画像の一覧。「寝取られ妻のビフォーアフター」に使うつもりで幅広いエッチ画像が出るようにプロンプト指定してあるので、あとは放置しておけばよいという…。ほとんどがそのまま採用できるクォリティですし、その上無限にある候補の中から目的に沿ったものをピックアップできる。しかも、無料で…なんと素晴らしいことでしょうか。 ローカルの魅力は十分に伝わったと思うので、「ぜひやってみたい!」と思った方はすぐトライしてみることをおすすめします。賢木のようにトラブルさえなければ、数時間ほどで最初の画像生成にこぎつけられます。NAIだけで満足しちゃうのはもったいNAI! 「Stable Diffusion web UI」導入方法まず、導入にあたってはドライブの空き領域を十分に作っておいてください。学習モデルは一つあたり4~8GBほどありますし、たっぷり空き容量がないと画像生成もできません。Cドライブ以外にインストールすることも可能ですが、エラーも起きがちなので、最初はCドライブで始めることをおすすめします。 1.Python 3.10.6をインストールする 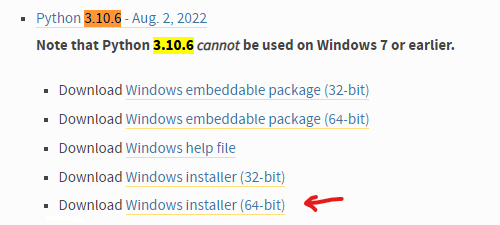 ・Python公式サイトにアクセスし、Python 3.10.6のインストーラーをダウンロードします。最新版ではなく、ちゃんとバージョン3.10.6を選びましょう(写真参照)。3.10.8を間違って入れ、うまくいかなかったケースがありました。 ・インストーラーを実行します。最初の画面で出てくる「Add Python 3.10 to PATH」にチェックを入れてから、「Install Now」をクリック。 ・無事「setup was successful」と表示されたら「Close」をクリックでOK。 2.Gitのインストール
・Git公式サイトのダウンロードページに行き、最新版へのリンクである「Click here to download」をクリック(写真参照) 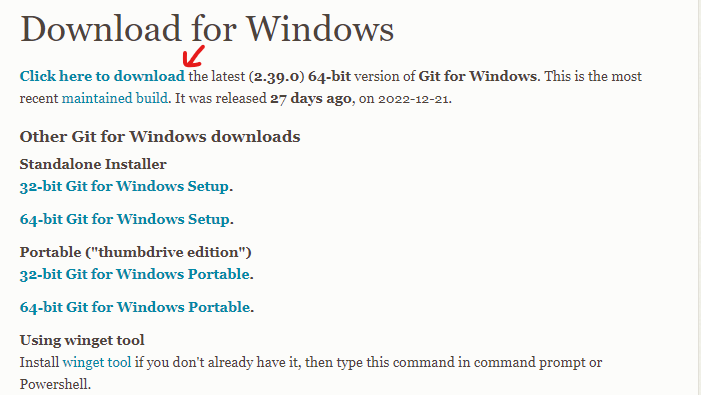 ・ダウンロードしてきた「Git-2.39.0.2-64-bit.exe」を実行(※記事執筆時点の最新バージョン) ・インストールボタンが出るまで「Next」を連打します。チェックマークは変更しなくてOK。「Install」が出たらクリックしてインストール。 ・インストールに成功したら、「View Release Notes」は見なくていいのでチェックを外し、「Finish」。デスクトップなどを右クリックしてこちらのメニュー(Git Bash Here)が生成されていたらOKです。 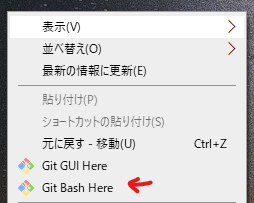 3.Stable Diffusion web UIのソースコードを入手する ・SD webUIをインストールしたい場所(Cドライブ直下がおすすめ)を開いて、右クリックして「Git Bash Here」を実行。 ・真っ黒な画面が立ち上がり「$」マークの横にカーソルが出るので、下記の文字列をコピーして「右クリック→Paste」。※Ctrl+Vは使えないので注意。~[[200~]などと表示されたらコピペミスです。コピーしてから右クリックする間にCtrl+Vを押してしまうと、なぜかクリップボード上でこうなってしまうようです。コピー→すぐ右クリックしてPasteを試してみて下さい。 git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git 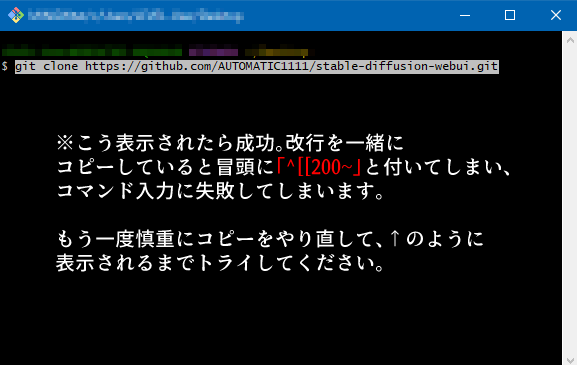 ・正しく入力できたらエンターキーで実行。これで先程右クリックした場所に「stable-diffusion-webui」フォルダが生成されます。 4.学習モデルを放り込む お疲れ様でした、ここまでの作業でゲームの「ハード」は入手できたことになります。あとはゲームソフトに当たる、先程説明したStable diffusionの学習モデルを入手すれば画像生成が可能になります。学習モデルは「.ckpt」もしくは「.safetensors」という拡張子で配布されている事が多く、「C:\stable-diffusion-webui\models\Stable-diffusion」のフォルダに放り込めば動作します(※Cドライブ直下にインストールした場合) 最初に放り込むモデルは何でも良いと書かれていることが多いのですが、賢木の場合はエラーが起きたので、公式で案内されている通り「stable-diffusion-v-1-4-original」で配布されている「sd-v1-4.ckpt」を入れることをおすすめします。ダウンロード方法は以下の通り。 ・まず、HuggingFace公式サイトから学習モデルをダウンロードするため、HuggingFaceのアカウントを作成します。公式サイトにアクセスし、画面右上のsign upをクリック。 ・登録したいメールアドレスとパスワードを入力して「Next」をクリックします。パスワードは相当複雑なものを求められるので、自動生成されるものを使った方がベターです。 ・ユーザー名、フルネームを入力したら、利用規約などを確認してチェックを入れ、「Create Account」をクリックすればOK。先程のアドレスにメールが届くので、そこから認証します。 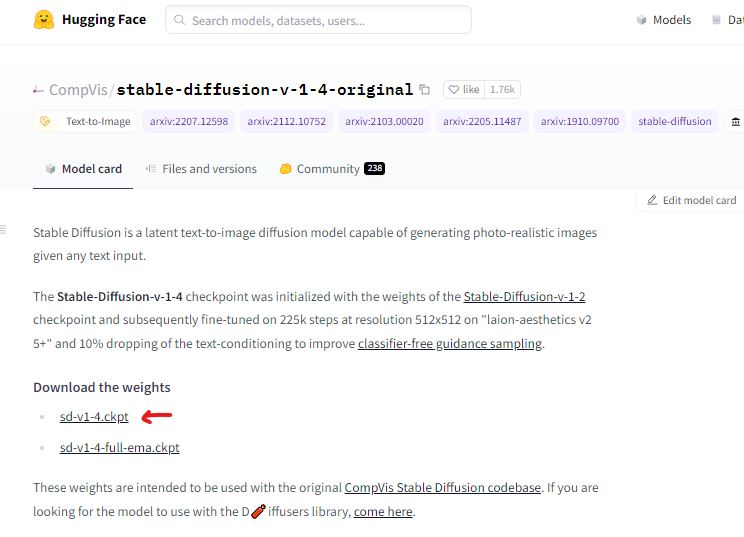 ・無事ログインできたら、「CompVis/stable-diffusion-v-1-4-original」にアクセス。画面中部の「sd-v1-4.ckpt」をクリックしてダウンロードしてください(容量が4GBあります)。保存先は「\stable-diffusion-webui\models\Stable-diffusion」です。親切に「Put Stable Diffusion checkpoints here.txt」という案内テキストが置かれているので間違えることはないでしょう。 【重要】アップデート方法Stable diffusion WebUIは解説が追いつかないほどの超スピードで更新されています。さまざまな新機能や便利機能をあまさず楽しむためにも、下記の手順でたまにはアップデートをすることを忘れないようにしましょう。 【Gitを使ったアップデート手順】
・(WebUIが起動している場合は黒いウィンドウを閉じて一旦終了してから)Stable Diffusion WebUIのインストールフォルダを開く
・インストールされたフォルダ内でShiftキーを押しながら右クリック。メニュー内の「PowerShellウインドウをここで開く」を選択 ・開いた画面に「git pull」と入力してEnterキーを押すだけでOK。しばらく待つと最新版にアップデートされます。 ついに実行ここまですべての準備が整ったら、SD WebUIのインストールフォルダを開き、実行ファイルである「webui.bat」を実行します。今後もWebUIを起動するときはこのファイルを実行するので、覚えておいてください。  黒いコマンドプロンプト画面が表示されて、環境整備が進みます。賢木はここで何度もエラーが表示されてしまい、大変いろいろと苦労したのですが(Pythonのバージョン違いの残滓が残っていたり、stable-diffusion-v-1-4の学習モデル以外を保存していたのがおそらく原因)、スムーズに行けば「Running on loal : http://~」というURLが表示されます。こちらをブラウザで開けば、おめでとうございます!ローカル環境のインストール成功です。 画面の見方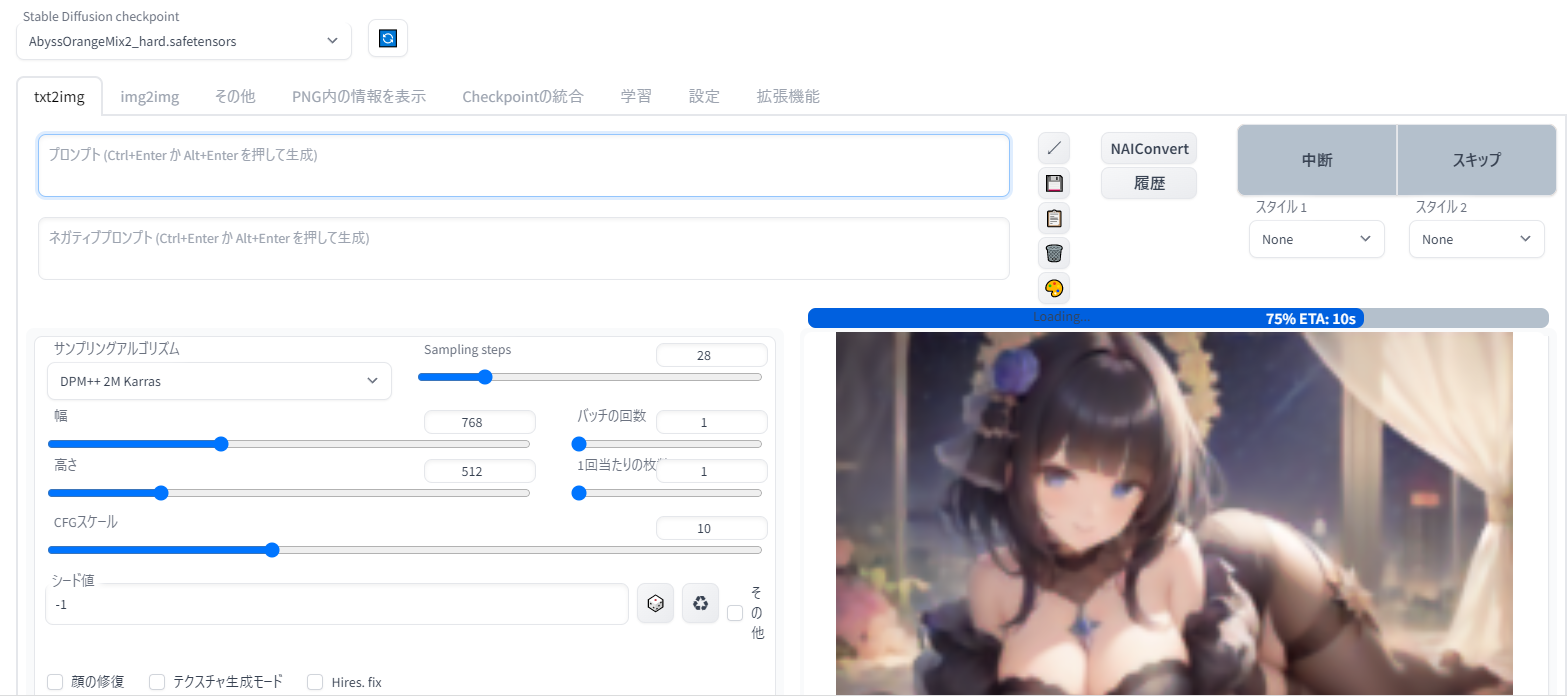 ※こちらの画面は日本語化済み。やり方は後述します。 ・画面左上のプルダウンメニューに、ゲームソフトに当たる「学習モデル」が表示されています。最初は「sd-v1-4.ckpt」しかありませんが、後述するさまざまな学習モデルを同じフォルダに入れ、ここのプルダウンメニューで選択することで、モデルごとに特化したイラストの生成を楽しむことができます。(写真では別の学習モデルが表示されています) ・基本画面は「txt2img」のタブ。NAIと同様にプロンプトとネガティブプロンプトを入力し、横縦のサイズを指定して、「genelate」ボタンをクリックすると、「C:\stable-diffusion-webui\outputs」フォルダに画像が生成されます。他にもi2iができるタブや設定のタブ、拡張機能を導入するためのタブなどがここから選べます。いきなり大きなサイズを作ったり、横縦のバランスが悪い画像を作ると、AIは上手に絵が描けません。基本はNAIのデフォルトサイズを参考にして、そのあと拡大しましょう。 ・「img2img」が元画像を入力してイラスト生成する「i2i」です。NAIと同じ通常のi2iやインペイント機能(元画像に直接描き込んで修正する)だけでなく、画像の一部をマスクで指定して描き直す「レタッチ」などのさまざまな機能があります。初期設定では、t2iで生成された画像とi2iで生成された画像は別フォルダに保存されます。 ※他人が著作権を持つ画像のi2i入力は厳に慎んで下さい。界隈では短期間に何度も他人が苦労して描いたイラストをi2iして自作品とする悪質行為が露見し、画像生成AIユーザー全体にとって大きなダメージとなっています。i2iパクリはどんなに加工しても元絵を知っている人にはバレますし、明確な著作権侵害行為であり、訴訟に発展する恐れもあります。絶対にしないようにしましょう。i2iしていいのは「自分でt2iした画像」「自分で描いた絵」「自分で撮った写真」と、それらを元に自分で加工した画像だけだと思って下さい。Google画像検索で出てきた画像をポンと放り込んでi2i・・・のようなことをしていると、いずれ大変なことになります。 ・「Sampling Steps」がNAIでいう「Step」、「CFG scale」が「Scale」にあたります。「Batch count」が一度に生成する画像の数。簡単ですね。 ・「Seed値」はNAIでも慣れ親しんだSeed値です。学習モデル・プロンプト・Seed・ステップ数・シード値などが同じなら、誰のPCでも同じ画像が生成されます。「-1」とあるのは、毎回Seed値を変える(=ガチャ)ことを意味するデフォルト設定。-1にしたいときは横のさいころボタンでいつでも呼び出せます。さいころの横の更新ボタンのようなものは、直前に生成したイラストのSeed値を呼び出すためのもの。同じ構図のままちょっとテイストを変えたいときに利用しましょう。 ・NAIにもあった「サンプリングアルゴリズム」は、ローカルでもとても重要です。ラーメンの「固め濃いめ多め」みたいな注文の違いだと思ってください。同じ指示でもイラストの風合いや絵作りの方法が変わってきます。おすすめは低ステップでもハイクォリティーで色合いの濃い「DPM++ 2M Karass」ですが、学習モデルによっては配布者がおすすめサンプラーを指定している場合もあります。 ・プロンプト欄の右にある斜めの矢印をクリックすることで、最後に生成したデータのプロンプトなどを復元することが可能です(教えてくださったお二方、ありがとうございました)。NAIはアクセスするたびに最後の設定が画面上に残っていますが、SDWebUIでは再起動のたびに初期化されてしまいます。画像サイズなどをいちいち入力し直すのは大変面倒なので、インストールフォルダ直下の「ui-config.json」というファイルをテキストで開くと、画像サイズやデフォルトのサンプラーなど、さまざまな初期設定をいじることができて便利です。 ▼便利な「PNG Info」 PNG Infoタブは、AI生成画像のプロンプトやSeed値、設定を呼び出せる画面。単に呼び出せるだけでなく、t2iやi2iの画面にそのデータを送ることができるので、簡単に生成の続きをやり直せる。Seed値もコピーされるが、そのまま生成すれば全く同じ画像が生成されるため、元画像から大きくテイストを変えたい場合はさいころボタンで「-1」にし直そう。 ウェブ上で見ることができる他の術師さんの画像でも、投稿先によっては内部データが上書きされていないので、ここに放り込むことでプロンプトや設定が読める場合があります。ただ、本人にプロンプトを公開するつもりがなかった場合、「盗み見」的なマナー違反と受け取られる可能性も。上手な術師さんから技術を学びたいときはMajinAIやちちぷいといったプロンプト公開を想定しているサイトを参考にしたほうがいいでしょう。 ▼日本語化について WebUIは英語表記ですが、拡張機能を利用してUIを日本語化することができます。
・画面上部の「Extension」タブをクリックし、「Installed」「Avaliable」「Install from URL」とある中の「Avaliable」をクリック
・「localization」の左に入っているチェックを外し、「Load from:」ボタンをクリック
・しばらく待つとExtensionリストが表示されるので、Ctrl+Fなどで「ja_JP Localization」を見つけ、右側にあるInstallボタンをクリックすれば拡張機能がインストールされます。
・機能を有効にするため、画面上部メニューの「Settings」タブをクリックし、画面左の一覧から「User Interface」をクリック。
・下の方にある「Localization (requires restart)」の「None」を「ja_JP」に変え、画面上部の「Apply settings」を押す。
・「settings changed: localization」と表示されたら成功です。画面上部の「Reload UI」を押すことで、UIがリロードされ日本語機能が有効化されます。 ▽画像ビューアーアドオンを入れてみよう 日本語化機能を導入したときと同様の手法で「image browser」というアドオンを入れてみると、今まで生成した画像を一覧にすることができます。PNG infoでは放り込んだ一枚しか情報を読み込めないのに対し、こちらの機能を使えば過去の生成画像の一覧からプロンプトや生成設定を読み込むことが可能になり、かなり便利になります。 ▼無限生成するには オレンジのGenerateボタンを押せば画像が生成されますが、右クリックして「generate forever」を選択すると、ストップするまで永遠に同じプロンプトで画像を作り続けてくれます。止めたいときは再度右クリックして「Cancel generate forever」です。単に「中止」しただけだとまたすぐ次の生成が始まってしまうので、キャンセルが先! ▼vaeファイルについて 学習モデルだけを導入すると、生成したイラストが妙に色あせて見えることがあります。多くの場合、その学習モデルを正しい色合いで描くために必要な「vaeファイル」が欠けていることが原因。例えば、学習モデルファイル「〇〇.ckpt」と一緒に「〇〇.vae.pt」というVAEファイルが配布されていたら、これも一緒にインストールしましょう。保存先は学習モデルのお隣に当たる「models/VAE」フォルダ。ここに「.vae.pt」ファイルを配置しておき、「setting(設定)」画面内の「Stable diffusion」タブから「SD VAE」を選択することで作動させることができます。 プルダウンメニューごとの設定内容は以下の通り。 ①auto: ckptと同名のvae.ptファイルを自動で読み込む NovelAIとローカル環境のプロンプト記法の違いNAIのプロンプトでは「{}で強調、[]で弱める」が基本でしたが、ローカルでは()を使う別のルールで呪文を作る必要があります。ここでは、{}式のものをNAI記法、()式のものをローカル記法と呼ぶことにし、違いを簡単に説明します。
NAIでは{}、[]をひとつつけるごとに、AIの注目度を1.05倍に強める(or弱める)ことができます。つまり、{}をひとつ増やすごとに1.05倍、1.1025倍、1.1157625倍と端数が出ていくことになるわけです。囲んだ{}の数で強さを示すのは視覚的に分かりやすいのですが、左右のかっこの数を間違えがちだったり、結局何倍なのか想像がつきにくかったり、そもそも打ち込むのが大変だったりと、一長一短がありました。
一方で、ローカル記法はこのようなルールになっています。
(long hair:1.2)のようにプロンプト中にスペースが入っても、()内の単語全体に効果がかかります(この場合hairだけでなくちゃんとblack hairの影響度が上がる。black_hairでも同じ)が、コロン「:」のあとに半角スペースが入るとうまく認識されないことがあると聞くので注意。 弱める[]を使った[word:1.1]という表記も使えません。
かっこ一つあたりの重みが強くなっていること、かっこの種類が一部違うこと、数字を使って強調度合いを直接指定できるようになったことが特徴ですね。まあt、NAIにはなかった特殊な記述ができるようになります。
▽呪文の途中変更(プロンプトエディティング)[A word:B word:X.X]という特殊な記法を使うことで、画像生成の途中からプロンプトを切り替えることができます。例えば[プロンプトA:プロンプトB:0.5]とした場合、画像生成までの全ステップのうち、前半まではAプロンプトが効き、後半にさしかかるとAプロンプトの影響が消えてBプロンプトのみになります。結果、生成画像上ではAとBの要素両方がある画像となります。(※数字はプロンプトに変化を起こすステップ数。0.8ならステップの最後の20%にさしかかると変化が生じますし、1以上の整数を指定した場合、その数字のステップで変化が生じます)
また、複数のプロンプトではなく[blue hair:0.5]のように単一プロンプトで指示すると、途中までは青い髪についての指示が存在しないものとして生成され、全ステップの半分にさしかかってからblue hairプロンプトを追加することもできます。コロンを二つにして[blue hair::0.5]とすると、逆に前半部分だけプロンプト指示がなされ、後半にさしかかるとそのプロンプトが除去されます。
これをうまく使えば、ステップ途中で「wearing clothes」→「naked」と変化させることで服を透けさせたり、複数の表情を混ぜたり、色が別の部位に移ってしまう「色汚染」を防いだりすることができるようになります。もっと高度であれば、全く別イラストのプロンプトと混ぜることで、要素が混じり合った新しい世界を生み出すこともできます。
【色汚染を防ぐ方法】AIの画像生成はステップの前半で大雑把な描画を、後半で細部の描画をしていきます。WebUIではその様子が視覚的に描写されるので、Stepの冒頭時点でまず全体をラフに形取っておおまかに着色しているのが分かると思います。おおざっぱなラフの段階で広い範囲に強い色が塗られてしまうと色汚染が起こるので、ステップの前半で範囲の大きい部分にA色を着色し、詳細な部分のB色は後半に塗ることで、指定していない場所への色汚染を防ぐことができます。
例えば[black::0.5] hair, [blue:0.5] eyeとすることで、前半ステップで髪を黒く塗り、後半ステップでは目を青く塗るので、髪の一部が青くなる現象を防ぐことができます。もちろん、ネガティブにblue hairを入れるだけでもこうした現象は防げますが、たくさんの色を部位ごとにより細かく指定したい場合には役立ちます。
[frog:cat:0.5] と[cat:frog:0.5]では「カエルの形をしたネコ」「ネコの形をしたカエル」と結果が変わります。前半でカエルを描くかネコを描くかによって大まかな形状が決まり、その後詳細を描く段で「これはカエル(ネコだ)」と指示するので、前後によって結果に差が出るというわけです。
▽オルタネイトプロンプト半角コロンを使うプロンプトエディティングはあるステップを特定してプロンプトを切り替える記述法ですが、コロンではなく縦線「|」を使うと、1ステップごとにプロンプトを交互に切り替えることもできます。例えば[frog|cat] というプロンプトでは、奇数ステップではカエル、偶数ステップではネコを描くので、さきほど説明したようなステップ前半後半における影響変化が起こらず、より各要素が混じり合います。[frog|cat|bird] の場合は、1ステップごとに カエル、ネコ、鳥が順番に入れ替わって描かれることになります。
▽ダイナミックプロンプトExtension画面でインストールすることで使えるようになる記法。{Aword|Bword|Cword}と記述することで、内部のプロンプトをランダム選択する。これによって、画像を大量生成するときに、雰囲気を統一しながらさまざまな風合いのキャラクターを生成できる。1girl have {blue|red|blonde}hairのように利用する。下記のようなより高度な指定方法も可能。
{2$$A|B|C}:3つのプロンプトのうち、どれか2つがランダムで選択される どの画像モデルがえちちなのか?初期設定のままワクワクして画像生成された方は、がっかりされた方も多いんじゃないでしょうか。私も一番最初に設定も何もいじらず生成した画像では、NAIに比べるべくもない変な少女が現れました。  これが記念すべき賢木のローカル生成イラストなわけですが、まあがっかりですよね。「みんながツイッターに投稿している美麗イラストはどうやったら良いんだ!」となりました。その後、stable diffusion以外の学習モデルをいろいろとインストールしてみたところ…
さきほどのと比べればいきなり美麗なイラストが生成できました!まだ思っていたのとは違うけど… ステップやスケール、サンプラーをどうしたらいいか全く分からなかったので、しばらくこの学習モデルで画像生成をあれこれ試してみました。最初に試した学習モデルはどれもとっても美しいイラストを描くことができるかわりに、男性器が出てくるようながっつりしたR-18(nsfw)はあまり得意ではなかったようで、nsfwなプロンプトを入れてもR-15程度の表現にとどまってしまうことが分かりました。賢木はもともとド下品エロ界隈の人間ですから、どうしたものかな…と思っていたところに、冒頭で紹介した賢者の皆様がさまざまな学習モデルを紹介してくださったという経緯です。 詳しくは後日また紹介しますが、現在賢木が使っているのは「abyssorangemix2」のnsfw版「hard」。日本人らしい肌色を再現でき、光の反射や水彩塗りを思わせる肌の質感がとてもグッとくる学習モデルです。「正しい指が生成される確率は約 30 ~ 50%」と公式は言っていますが、NAIに慣れていた私から見ると正直なところ神レベル。少々おかしくったって、WebUIならピンポイントのi2iレタッチができるので、指の修正も簡単です。 公式によると、サンプラーは「DPM++ SDE Karras」、「Steps」はサンプル集めなら12以上、イラストレベルなら20以上がおすすめとのこと。abyssorangemix2には「_sfw」「_nsfw」「_hard」の3種類があり、後者ほどえちち度の高い画像生成に向いています。
賢者の皆様のおかげで出会えた最高のエロモデル、記念すべき最初のイラストを加工したのがこちらの作品。一撃目でこのレベルとは…。 ちなみに、下記のフェラチオプロンプトとうちのヒロイン綾香ちゃんの生成呪文を混ぜて朝までforever生成させたところ、うちの骨董品グラボGTX1060でも600枚ほど生成されていました(その後RTX3060に変更)。手が変だったり男性器が空中に浮かんだりといった破綻があったのは1-2割程度で、ほとんどそのまま同人に使えるレベル。髪の長さはブレますが、顔面は統一感があります。  プロンプト:masterpiece, best quality,(fellatio:1.5),\(nsfw:1.1576\),(erotic:1.2155),licking,pov,steam,netorare,1boy and 1girl,nipples,sweat,wet skin,(fucked silly:1.5),eye contact,vulgarity,on bed,pubic hair,dark room,simple background,seductive smile,(completely nude:1.2),cum,(masterpiece:1.1576),(high resolusion:1.2155), (illustration:1.05),(ultra detailed 8k art:1.05) いやあここまでとは…昼間は必要な画像を生成しておいて、夜は過去の製作ページとの差し替えが短期間でできそうです。もっと早くやっておけばよかった!でも昨日がんばって本当によかった! というわけで、またも眠れない夜が続きそうな賢木でした。まだまだ学習モデルやi2iについてなど書ききれないのですが、今日はここまでとします。この記事は呪文辞典と同様に今後も加筆修正していきますので、どうぞよろしくお願いいたします。 それでは皆様、良きAIライフを!「AIでエロを変えたい!」スタジオ真榊でした。
いつもわかりやすい記事をありがとうございます。 記事中で提示いただいたプロンプト、ネガティブプロント内の数字(1.5や1.2等)は、どういった意味を持つのでしょうか。すでに解説済みでしたら申し訳ございません。
[ 2023/01/20 12:56 ]
[ 編集 ]
記事を参考に試してみたところwebui.batの起動で詰まってしまいました。Pythonのバージョンや他のモデルを入れていないか、ファイルの場所がおかしくないかなども確認しましたがうまくいきませんでした。 解決策などわかりますでしょうか。自分もAIに興味があり是非使ってみたいと思っているのですが。
[ 2023/01/21 08:27 ]
[ 編集 ]
『stable diffusion model failed to load exiting』となってしまったのですが解決方法などわかりますでしょうか。
[ 2023/01/21 21:35 ]
[ 編集 ]
どうやっても生成したイラストが若干色褪せる、ぼやけてしまうのですがどうしたら皆様のような綺麗なイラストができるのでしょうか?
[ 2023/01/21 22:03 ]
[ 編集 ]
いつもながら詳しい記事感謝。 知識0の状態でしたがおかげさまで無事に導入出来ました。 モデルの紹介記事も楽しみに待ってます!
[ 2023/01/22 07:43 ]
[ 編集 ]
前々から何となくローカル版も気になってましたが、管理人様もついに導入されたとのことで当記事を参考に私もローカル版導入にチャレンジし、無事に環境構築に成功しました! 確かにこれは一度ローカルでの無料無限生成の味を知ってしまうともう本家NAIには戻れなくなってしまうというのも頷けますね。凄まじい魅力です。 今後は管理人様によるローカル版関連の技術記事にも目を通していきたい所存です。 オススメの学習モデルや、それらモデルの導入方法についての記事など、楽しみにしています。
[ 2023/01/24 20:51 ]
[ 編集 ]
共有_ stable diffusion model failed to load exitingとなってしまう方々 自分もいろんな記事を検索してみました、ライセンス読んでアグリーしてないからだとか、extension消したらうまく行くよだとかいろいろ書いてありますが、たぶんグラボのメモリ不足です。 該当のエラーが出る直前、確かにグラボのメモリが上限までいってました。。。 確かにエラーが出る時直前の内容を見ると、「メモリがこれだけ必要なのに空きが0じゃねぇかボケ」 って怒られてますね ちなみに自分は1050です。 主は1060で動いたらしいので、ぎりぎりダメなんでしょうね。 かといってグラボも高いし、これが100%原因とも言い切れないし考えどこです
[ 2023/01/31 08:31 ]
[ 編集 ]
できました! こんばんは、はじめまして。ものすっごい有益な情報を詳しく載せていただきありがとうございます! とってもエチエチな絵が作られていって、フォルダの中を覗くのが楽しいです(●´ϖ`●)♥ NTR、M成分も大好きなのでこれからも応援しています!
[ 2023/02/01 05:08 ]
[ 編集 ]
承認待ちコメント このコメントは管理者の承認待ちです
[ 2023/02/08 23:36 ]
[ 編集 ]
承認待ちコメント このコメントは管理者の承認待ちです
[ 2024/11/14 08:58 ]
[ 編集 ]
コメントの投稿 |
|





























copyright © 2024 ゲス顔イオナズン all rights reserved.