ゲス顔イオナズン
Stable Diffusion✕AIイラスト徹底解説!
 |  |  |
 |  |  |
 |  |  |
最新のControlnetで差分イラストを作ろう!(表情・服装編) 珍しく日中からこんにちは!スタジオ真榊です。
今日ははいわゆる「差分」の作り方に関する記事をお届けします。差分と言えば、表情差分やポーズ差分、服装差分や背景差分、セリフ差分など、主にイラストやゲームなどにおける画像バリエーションのことですね。
AIイラストでは、これまでも主にマスク部分のimage2imageを使った差分作りが行われてきましたが、このところControlnetやジェネレーティブ塗りつぶしをはじめとしたさまざまな技術がそろってきましたので、この記事では2023年6月現在の最適解を探ってみたいと思います。
今回元画像として使用するのはこちらのイラスト。
 実験では、こちらのイラストの表情差分・服装差分・背景差分・ポーズ差分を作ってみます。ちょこちょこ書き進めていたのですが、ずいぶん長い記事になってしまったので、前後編に分けてお届けしたいと思います。 余計な部分を消しゴムマジック!LamaCleanerでできる「修正」と「粗密」 こんばんは、スタジオ真榊です。世間がAdobeの画像生成AI機能「ジェネレーティブ塗りつぶし」に揺れている中、今夜は「消し」に特化したインペイントツール「LamaCleaner」についての検証記事をお伝えします。というのも、ジェネレーティブ塗りつぶしについて検証を行っていくに当たって、その前にどうしても触れておかざるを得ないツールだからなんですね。
「LamaCleaner」は、画像の中に映り込んだ余計なものをマスクすると違和感なく消してくれる「消しゴムマジックで消してやるのさ」的なツール。やろうと思えばSDwebUIのinpaint機能でも似たことができるわけですが、スピードや手軽さが段違いで、非常にスムーズに「消し」や「なじませ」ができます。一方で、今話題の「ジェネレーティブ塗りつぶし」は「消し」だけでなく「足し」もできるツール。普段の画像生成にそれぞれどのように活かせるか、前後編に分けて見ていきたいと思います。 【Controlnet1.1】新モデルをフルに使って試す「写真とイラストの融合」 こんにちは、スタジオ真榊です。皆さんGWの真っ只中でしょうか?賢木は休みでも休みじゃなくてもSDwebUIをめっちゃ楽しんでおります!
さて今日はControlnet1.1の全体検証とまとめ記事が一段落ついたのを受けまして、以前のこちらのツイートのように「CN1.1の最新モデルを組み合わせたらどんなことができるのか?」を検証してみたいと思います。
写真とイラストの融合はできるのか?controlnet1.1をフルに使うと言っても、色々な組み合わせ方があるわけですが、まず最初に思いついたのが自分で撮影した写真をイラスト化できるのか?ということ。賢木は(もちろんド素人ですが)スマホで写真を撮るのが大好き。「いろいろな場所で撮影した風景写真をイラストに取り込むことができたら、作品の幅が非常に広がるのでは」と常々思っていました。
これを思いついたのは、こちらの「wama@iphoneで3Dスキャンする人」さんのツイートを拝見したとき。
写真を繋ぎ合わせて一つの3Dデータにしてしまい、スマホの中に保持していつでもどんな画角でも呼び出すことができる…いまはこんなことが簡単にできてしまうのですね。
例えば、あるホテルの室内をiphoneで3Dスキャニングしておけば、あとで室内のいろんな背景を自由に画角を動かして再現できるわけです。それを漫画作品の背景にもし使えたとしたら、なんと画像生成AIの弱点だった「背景の同一性」を難なく担保できてしまうのですよ。例えば、エロゲなんかでは室内の背景素材があったとしたら、せいぜい「昼」とか「夜」とか「ズームアップ」といった差分を作るくらいで、その前でキャラの立ち絵をカチャカチャ動かして場面を表現していたわけですが、もし実在の室内データを3Dで保持できたら、ベッド上でもソファに座っているところでも入室時のコマでも、なんでも簡単に背景素材画像にすることができます。 3Dにするときにもちろん画質は落ちますが、基本的な主線や凹凸さえ保持できていればControlnetでイラスト化できるわけですし、撮影OKな場所であれば権利問題もクリアできますね。
とまあ、夢は広がるばかりなのですが、そもそも今回の主題である「風景写真とイラストとの融合」ができなくては取らぬ狸の皮算用。できるのか?できないのか?まずは検証をやってみましょう。 アップスケール?描き直し?新モデル「Tile」ができること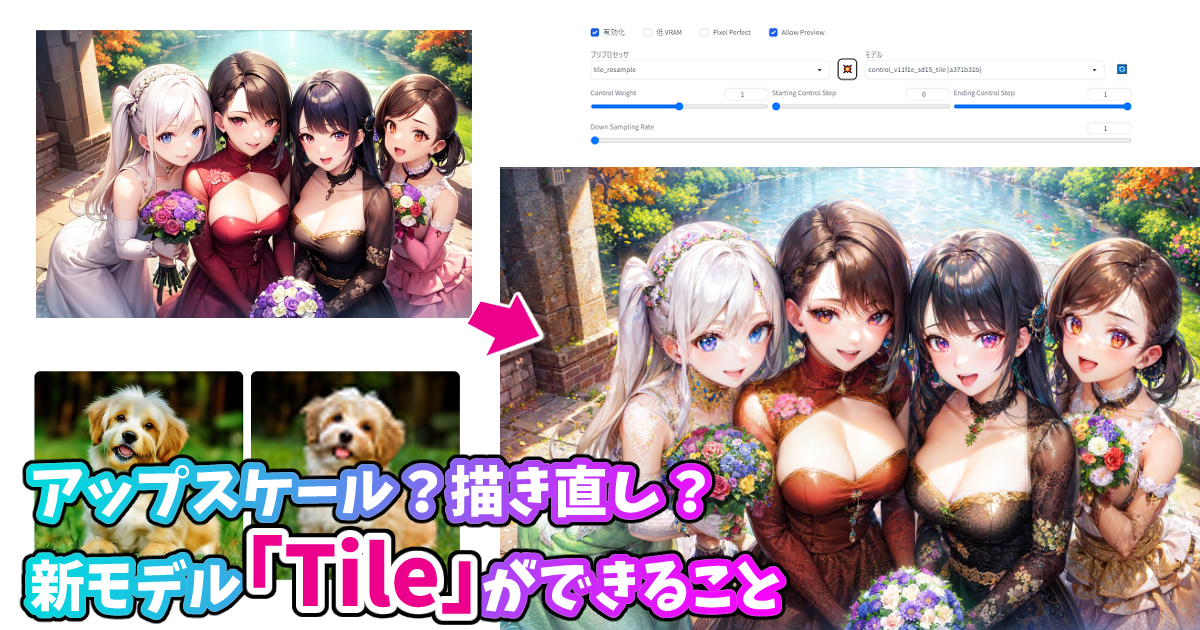 こんばんは、スタジオ真榊です。今夜は2023年4月25日付で完成したばかりのControlnet1.1用モデル「Tile」についての報告です。Controlnet1.1で使えるものの中でもひときわ異質なこのモデル。アップスケール用なのか?それともCannyやDepthのように構図を写し取るためのものなのか?いろいろと検証してみました。
※Controlnet全体についての基本的な使い方や各モデル紹介については、こちらの記事(▼)をご参照ください。
 Tileってどんなモデル?Controlnet1.1が公開された当初、Tileは「未完成」という注釈つきのモデルでした。モデル一覧では「control_v11u_sd15_tile」が公開され、プリプロセッサ一覧には入力画像にガウスぼかしを掛ける「Tile gaussian」というものが掲載されていました。その後、2023年4月25日に「完成」がアナウンスされ、新たなモデルとして「control_v11f1e_sd15_tile」が公開。「Tile gaussian」は「tile resample」に姿を変た…という経緯があります。 一体、何ができるモデルなのか?公式に書かれている説明は下記のようなものです。
・このモデルはさまざまな方法で使用できますが、大きく分けて、次のような2 つの動作をします。 わかるような、わからないような。
例えば、64×64の小さな犬のアイコンをそのまま8倍の512×512にズームすると、
  このようにぼやけてしまいます。 これは元画像のディティールが画像縮小の影響で失われてしまっているためですね。これを入力画像にしてi2iで高品質にしようとしても…
 元画像の「低品質な細部」にひっぱられて、このように低品質な画像ができてしまいます。 Tileはこうした「低品質な細部」を無視しつつ、もとのアイコンの犬の全体の形を保ちながら、アイコンに存在しない詳細な毛並みに置き換えてくれるというものです。
こちらの画像をご覧ください。
 これは、i2iではなくt2iで、先程の64x64pxの画像をTileで読み込ませて512x512で生成したもの。元画像になかったディティールが追加されていることが分かると思います。
「おお、じゃあこれ、アップスケール用のモデルなんですね?」と思うところですが、公式はあくまで「アップスケールもできるが、本来はディティールの置き換え(または追加)を行うモデル」だと念を押しています。
公式が提案する「Tileの使い方」は次の5つ。
①2倍、4倍、または8倍のアップスケールができる このうち、①のアップスケールについては、ほかのアップスケーラーのようにイラストを高解像度化するのではなく、「イラストに描かれたものを認識し、より高い解像度でゼロから描き直す」のだというのです。一体どういうことなのか?それを今回検証していきたいと思います。 Controlnetが理解る!モデル15種&プリプロセッサ35種を徹底解説★FANBOX記事の前半部分までを無料公開しています こんばんは、スタジオ真榊です。今回はStableDiffusionwebUIに大きな革命をもたらした拡張機能群「Controlnet」の大型解説記事です。2023年春に登場した「ver1.1」について、2023年4月27日時点で使用できるモデル14種とプリプロセッサ全35種のそれぞれの特徴とできることを検証しました。
Controlnetには、線画だけを抽出できる「Lineart」やポーズだけを抽出できる「Openpose」といったさまざまなモデルがあり、それらを有効に動かすための下ごしらえをする「プリプロセッサ(前処理機能)」というものが用意されています。
今回の記事は、それぞれの組み合わせやパラメータ設定、それによってできることなどを詳しく解説していく「総論」的な解説。「各論」に当たる各モデルの詳しい検証記事もリンクしてありますので、ぜひご活用ください。 目次インストール&アップデート方法 新モデル「inpaint」でイラストの続きを描いてもらおう!【Controlnet1.1検証】 こんばんは、スタジオ真榊です。前回の「Pix2pixでイラストを変化!10種の実験で分かったこと」に引き続き、今回もControlnet1.1でできることを検証していきます。
今回紹介するのは、新モデル「inpaint」。これはその名の通り、マスクした部分を描き直すインペイント機能に特化したControlnetモデルです。とはいえ「image2image画面で通常のインペイントをするのとどう違うの?」というのが最初に覚える疑問。text2textの画面でどうやってインペイントすればいいのかも含め、何ができるようになったのかを検証していきましょう。
なお、この記事では、img2imgタブで利用する従来のinpaint機能を「i2iインペイント」、今回検証するcontrolnet1.1のモデルとしてのinpaintを「inpaintモデル」と呼んで区別することにします。 目次実験:髪色を変化させる 実験:服装を変化させる 実験:表情変化を試す
実験:崩壊した手を直せる?
実験:イラストの一部を消して置き換える
実験:続きを描いてもらう「outpaint」
「Pix2pix」でイラストを変化!10種の実験で分かったこと【Controlnet1.1検証】 こんにちは、スタジオ真榊です。前回の記事に引き続き、今夜もControlnet1.1の新モデル検証の続きをお届けしたいと思います。
今回検証するのは「Pix2pix」。前回はイラストの要素をばらばらにして再構成する「Shuffle」について研究しましたが、Pix2pixは再構成ではなく「変化」を扱う新技術です。Controlnetのアップデートに注意しながら、さっそく見ていきましょう。
目次
・元イラストを変化させられる「Pix2pix」 ※今回の検証には一部、着衣状態の女の子を脱衣させる実験が含まれます。ご注意ください。
元イラストを変化させられる「Pix2pix」Pix2pixは「ペア」になった画像を教師データとして大量学習させることで、AIに二つの画像の間の「関係性」を覚えさせ、ある入力画像を渡すと指示通りに変化させて出力させられるようにする技術のこと。例えば、赤いリンゴの絵と青いリンゴの絵をペアで学習したAIは「Aを青くしたものがB」という関係性を学びますので、「このイチゴを青くして」という要求に応えられるようになる・・・というわけです。
 こちらの例では、「ひまわりをバラに取り替える」「空に花火を加える」「果物をケーキに置き換える」といった指示プロンプトによって、その通りに画像が変化していることが分かります。
「ある画像を入力して別の画像に変換する」という意味ではShuffleに似ていますが、Shuffleがあくまで元画像をピースとしてパズルをくみ上げる「再構成」のイメージなのに対して、Pix2pixはあるお題を任意の状態に「変化」させるイメージ。Shuffleと違って元イラストの色合いや要素を必ずしも継承しないので、入力画像と出力画像の雰囲気が似ないこともありますし、変化させる対象(上の例なら花や空、コートなど)を限定して置き換えることもできます。
|
|






















copyright © 2025 ゲス顔イオナズン all rights reserved.